How We Stopped Our AI Agent From Looping on Wikipedia Pagination
Naive graph crawlers burn their entire page budget on pagination archives and mirrored press releases before reaching a single content page. Here's the deterministic fix we shipped — and the numbers.
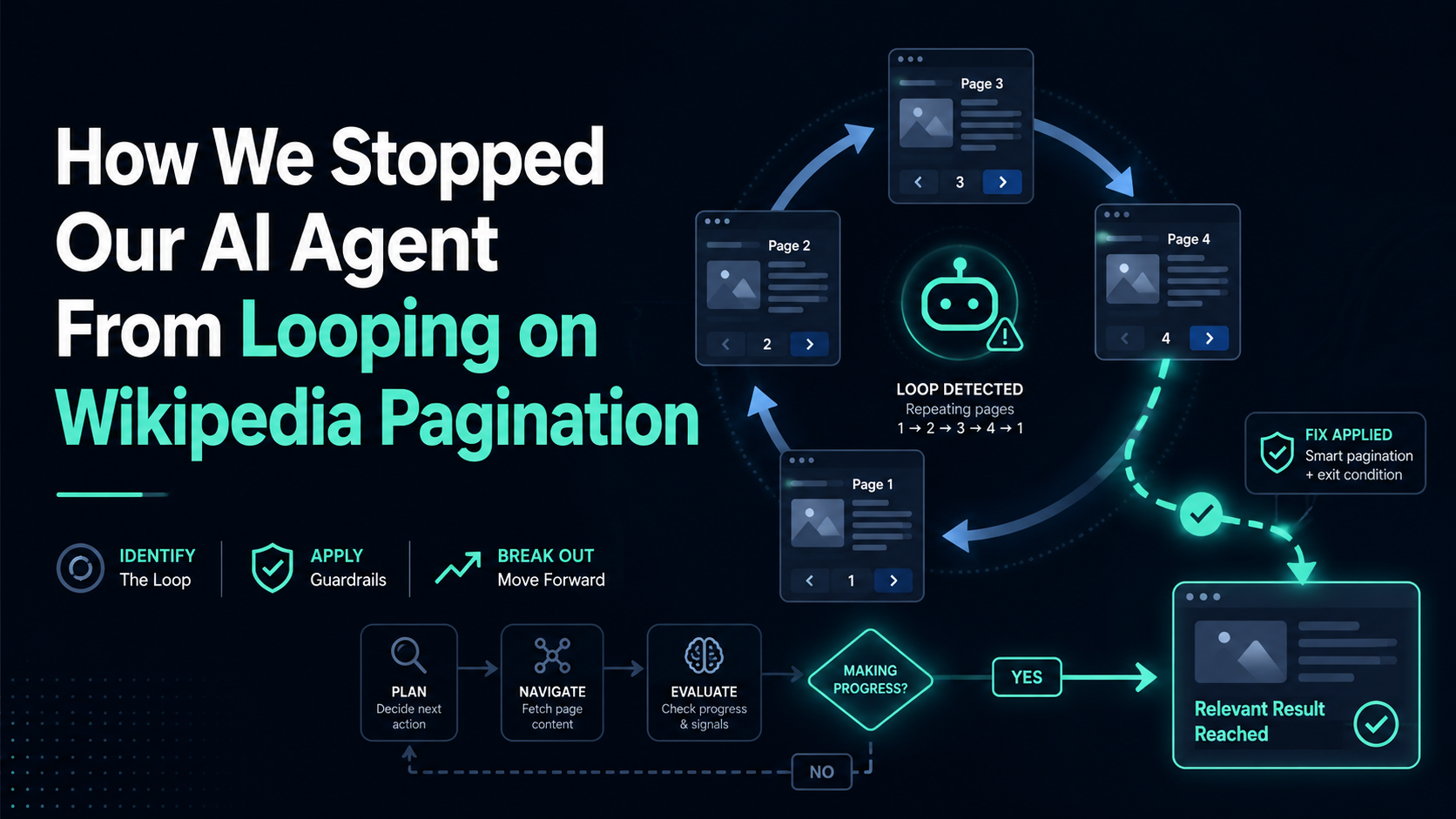
We run Gyrence, a web retrieval API purpose-built for AI agents. When we started stress-testing Gyre — our graph traversal primitive — against real sites, we kept hitting the same failure: agents looping forever on pagination, taxonomy archives, and user-generated tag clouds. Here's what we built to fix it, with real numbers. The problem: every href is not equal A naive breadth-first crawler treats every outbound link identically. On a content site, that means queuing:
We run Gyrence, a web retrieval API purpose-built for AI agents. When we started stress-testing Gyre — our graph traversal primitive — against real sites, we kept hitting the same failure: agents looping forever on pagination, taxonomy archives, and user-generated tag clouds.
Here's what we built to fix it, with real numbers.
The problem: every href is not equal
A naive breadth-first crawler treats every outbound link identically. On a content site, that means queuing:
/articles/page/2,/articles/page/3…/articles/page/847/tag/python,/tag/javascript,/tag/ai— one page per tag, thousands of tags/author/alice,/author/bob— one page per contributor/privacy,/terms,/cookie-policy— zero information value
An agent crawling a documentation site with a 50-page budget can exhaust it entirely on pagination before reaching a single content page.
The fix: deterministic graph pruning
We built a 25-pattern default prune list that fires on every link before it enters the queue — zero API cost, zero latency:
Pagination: ?page=, ?p=, ?offset=, /page/, /pages/
Taxonomy: /tag/, /category/, /author/, /topic/, /archive/
Legal: /privacy, /terms, /cookie, /legal, /gdpr
Auth: /login, /logout, /cart, /checkout, /account
Ad/tracking: /ads/, /analytics, doubleclick.net
Callers can extend the list with prunePaths or disable it entirely with allowPrune: false when they genuinely need to crawl those paths.
The second problem: mirrored content
Press releases, SEC filings, and syndicated articles appear on dozens of domains simultaneously. Without deduplication, an agent following outbound links from a financial news page will fetch the same earnings release from PR Newswire, BusinessWire, GlobeNewswire, the company IR page, and forty regional news outlets — identical content, forty API calls.
We implemented simhash fingerprinting: a 32-bit content hash computed from 4-gram shingles of each page's normalized markdown. Two pages with ≥85% content overlap (Hamming distance ≤ 3 bits) are treated as near-duplicates. The page is still returned — the agent sees it — but its outbound links are pruned. One press release spawns one crawl branch, not forty.
The numbers
On a benchmark crawl of a major financial news site (50-page budget, cross-domain enabled):
- Without pruning: 41 of 50 pages were pagination or taxonomy archives. 9 content pages reached.
- With pruning: 47 of 50 pages were unique content. Pagination and taxonomy: 0.
- Simhash dedup: 23% reduction in outbound link queue depth on a typical news crawl. On a syndicated press release crawl: 67% reduction.
Cross-domain hop control
For research agents that need to follow citations across domains, we added maxHops — a parameter that counts domain boundaries crossed from the seed URL. maxHops: 1 follows one external link per branch and stays on the destination domain. Without this, a cross-domain crawl is unbounded; with it, the agent controls the blast radius.
What we didn't build
We evaluated LLM-based link ranking — using a language model to score each outbound link's relevance before queuing it. The quality improvement was real but the cost wasn't: a 20-page Gyre with 30 links per page would require 600 LLM calls just for link prioritization, adding ~$1.80 per crawl at Haiku pricing. We parked it as an opt-in parameter (linkRanking: "llm") and shipped the deterministic version instead.
Try it
import requests
r = requests.post(
"https://www.gyrence.com/api/v1/gyre",
headers={"Authorization": "Bearer YOUR_KEY"},
json={
"url": "https://docs.example.com",
"maxPages": 20,
"sameDomain": True,
# prunePaths merges with the 25-pattern default list
"prunePaths": ["/changelog/"],
},
)
pages = r.json()["data"]["pages"]
print(f"Fetched {len(pages)} unique content pages")
Full API reference at gyrence.com/docs/api/gyre. Get an API key at gyrence.com.